Fabrizio Cominetti

📌 Data Science at University of Milano-Bicocca
📌 Digital Editor at AC Milan
Portfolio
SELECT * FROM sections
University
Master’s Degree in Data Science | University of Milano-Bicocca | GitHub
Collection of projects realized for the university courses of the MS at UniMiB (2021-2024).
Master’s Thesis
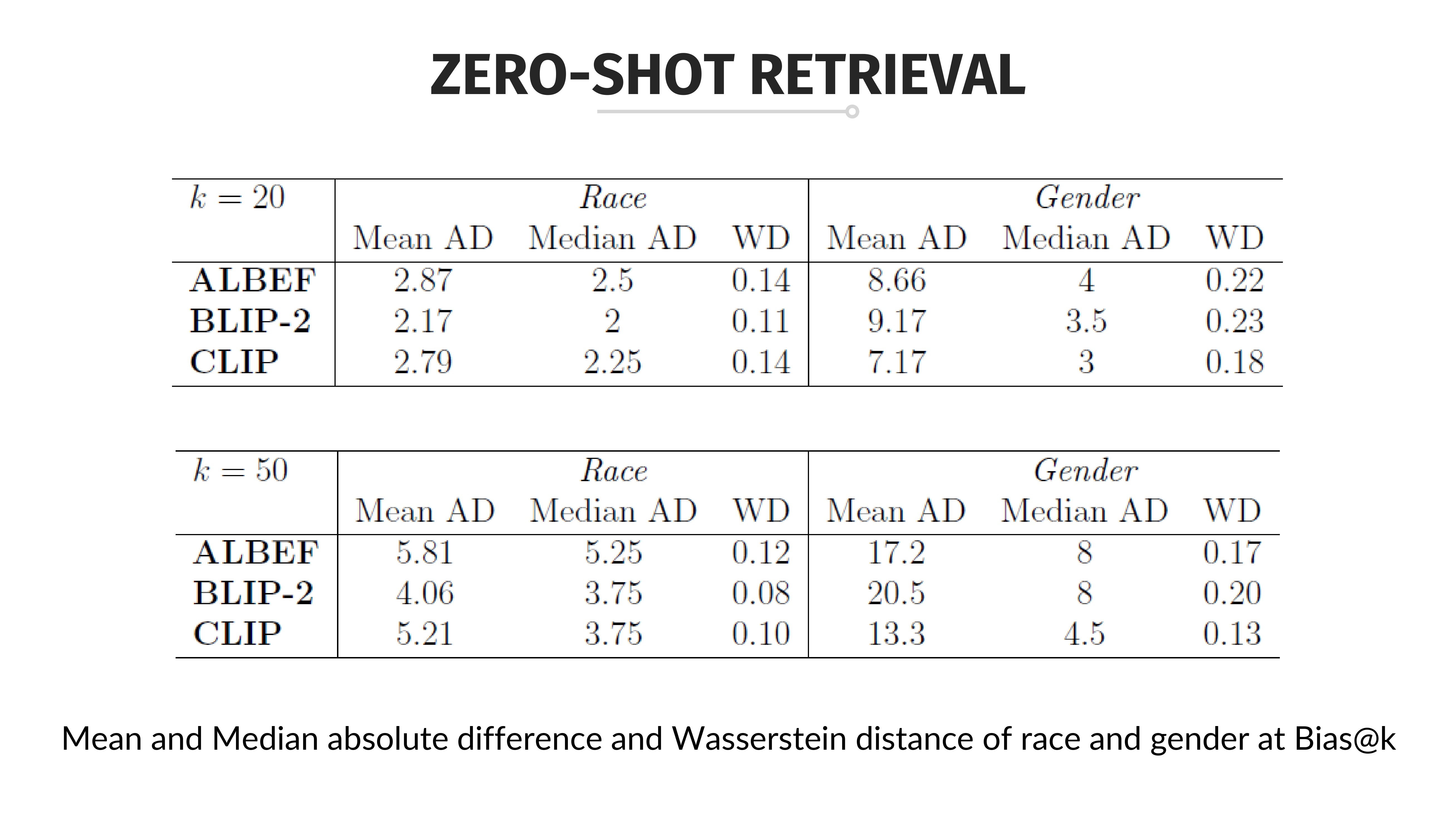
Exposing Bias in Vision-Language Models
Multimodal models have brought about significant and rapid technological innovations in recent years. Among these, vision and language models excel at processing, comprehending, and manipulating data and information from two modalities: text and image, representing textual and visual components, respectively. However, the possible presence of bias represents a significant concern that can overshadow their impressive capabilities. Starting with the construction of a novel and morphed dataset derived from UTKFace, this paper utilizes three pre-trained models - ALBEF, BLIP-2, and CLIP - to investigate gender and racial biases in VL models. The experiments span from zero-shot retrieval to zero-shot classification tasks, aiming to identify and measure bias across specific demographic groups. The findings contribute to advancing fair artificial intelligence by emphasizing the importance of addressing biases, particularly within these increasingly adopted models.


Social Media Analytics
Smart Working - Social Network and Content Analysis | Social Media Analytics, UniMiB (2023).
This project focuses on the analysis of the Twitter community and sentiment regarding the enunciated topic. Through the API, 2667 tweets related to the selected keywords were collected from December 26, 2022 to January 5, 2023. After an initial preprocessing phase based on text mining techniques, a Social Network Analysis (Nodes Degree, Assortativity, Community Detection) and a Social Content Analysis (Sentiment Analysis, Emotion Recognition) were performed.

Financial Market Analytics
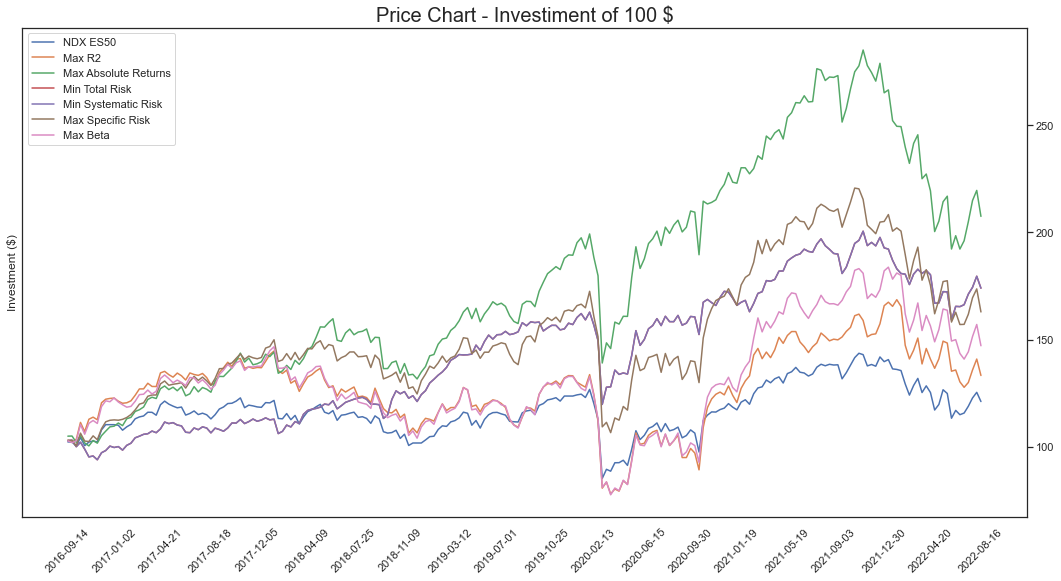
Portfolio Analysis | Financial Market Analytics, UniMiB (2022).
In this group work, we want to better understand the structural characteristics that risk brings to real investment portfolios. In order to understand this empirically, we need to build real portfolios that are concentrated/tilted with respect to a specific level and kind of risk.
The results showed that the portfolios created over-performed compared to the index during the period under consideration. However, the same results also showed higher volatility than that of the index.
Machine Learning
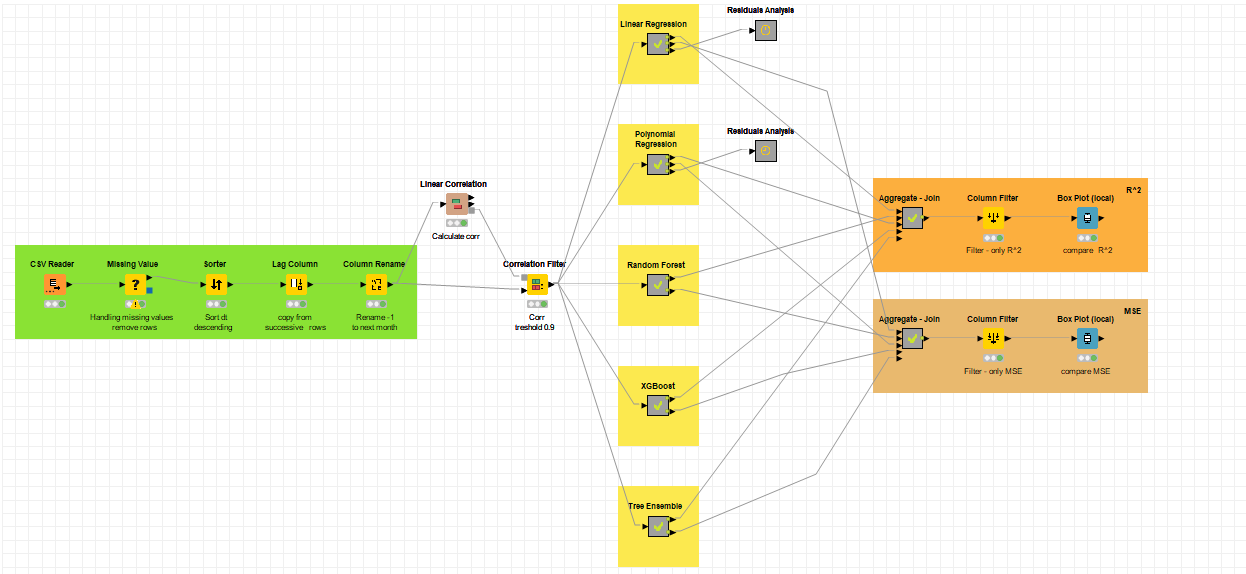
Climate Change - Temperature Prediction | Machine Learning and Decision Models, UniMiB (2022).
The project, conducted using the Knime platform, consists in the analysis of various regression models applied to a dataset containing environmental information referred to the global temperature from January 1750 to November 2015. The purpose is to develop and subsequently analyze various regression models with the aim of predicting the average global temperature of the next month, based on the data collected during the previous month.
Data Management
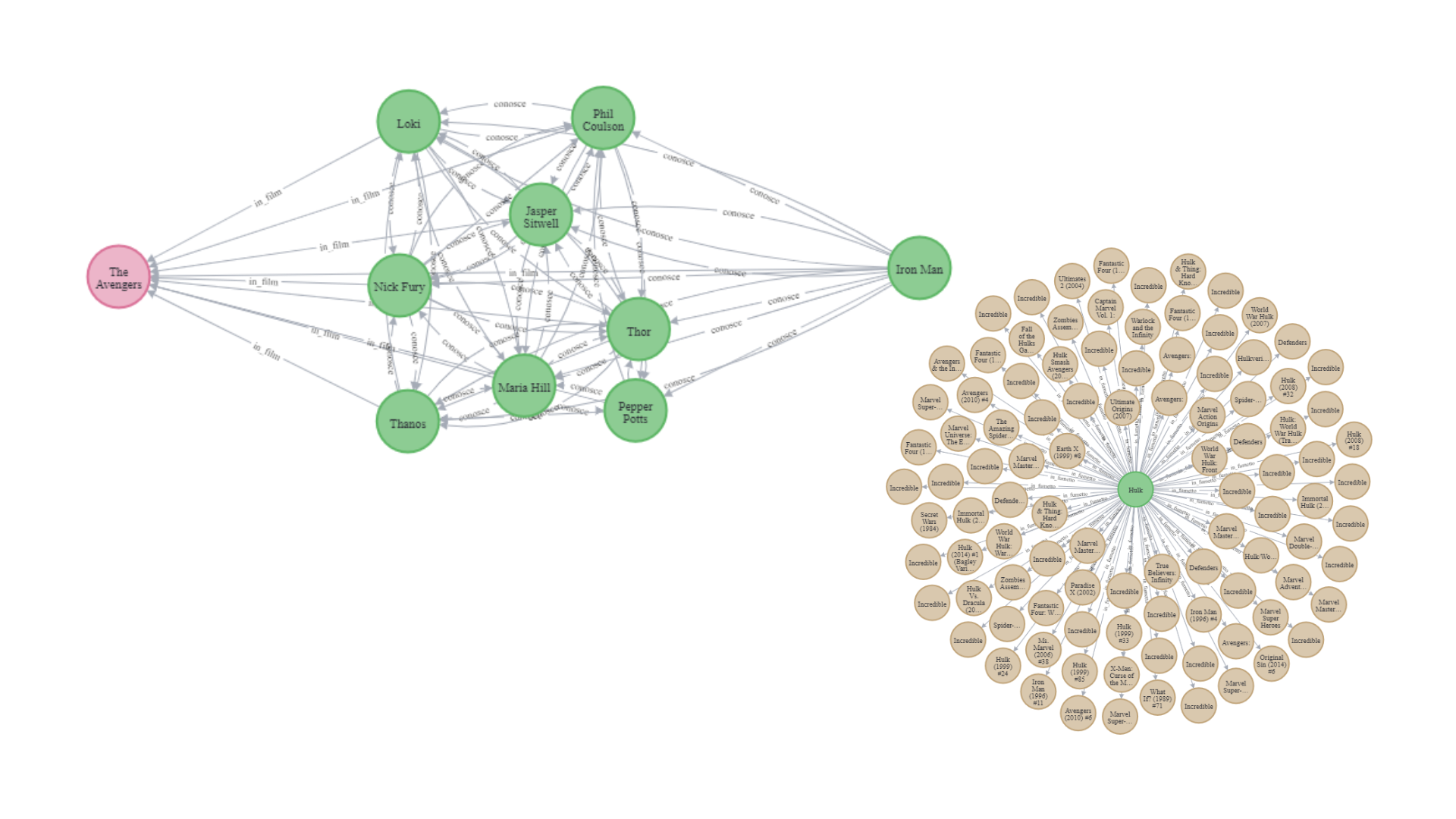
Marvel Graph Database | Data Management, UniMiB (2022).
The project realized aims to create a graph-database containing the relationships between the various Marvel products. For the realization of this project we have chosen a non-relational graph-database, built through the use of Neo4j. We have realized this project starting from two data sources, API and web scraping, that we have then integrated and on which we have then performed a quality check.
The final database is complete of the various relationships between characters, movies and comics of the Marvel world, moreover each node contains several information about its nature.
Data Visualization
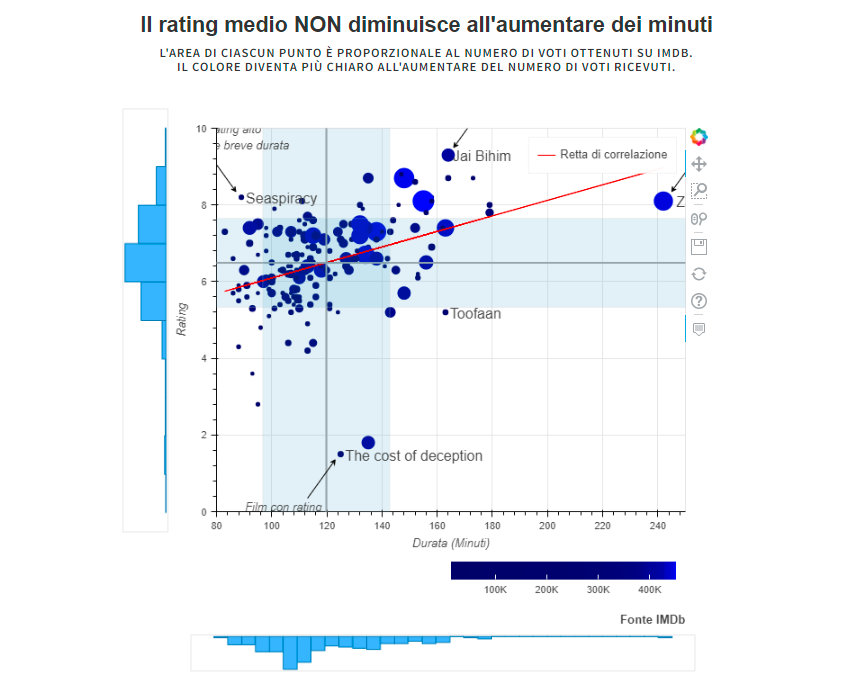
Film - Rating and Duration Time | Data Visualization, UniMiB (2022).
In today's attention economy and society is it true that people also prefer shorter films? This consideration guided us in the realization of this project and allowed us to determine the following research question: do shorter films generally receive better ratings?
We have therefore used the datasets provided by IMDb to answer the research question through an interactive visualization, utilizing the 'Bokeh' package for the final visualization.
Text Mining and Search
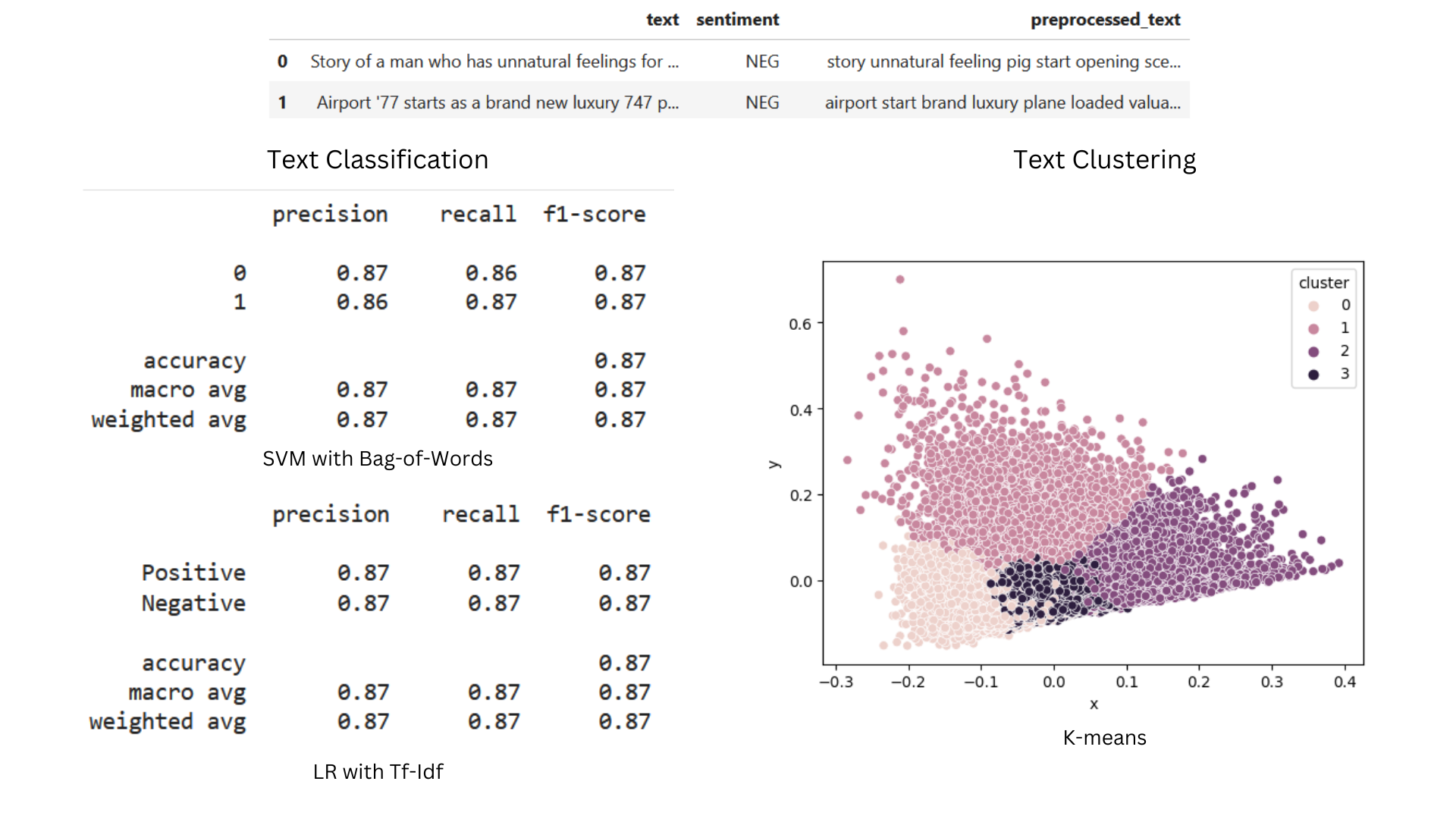
IMDB Reviews - Text Classification and Clustering | Text Mining and Search, UniMiB (2023).
In this project, user reviews from the IMDB platform were analyzed through the use of text mining techniques. After carrying out an initial phase of text processing and text representation, the project continued with the classification of the reviews, through some text classification techniques - such as Support Vector Machines (SVM), Multilayer Perceptron (MLP), and Logistic Regression. Next, a text clustering phase was carried out through the use of two algorithms: DBSCAN and k-means.
Data Science Lab on Smart Cities
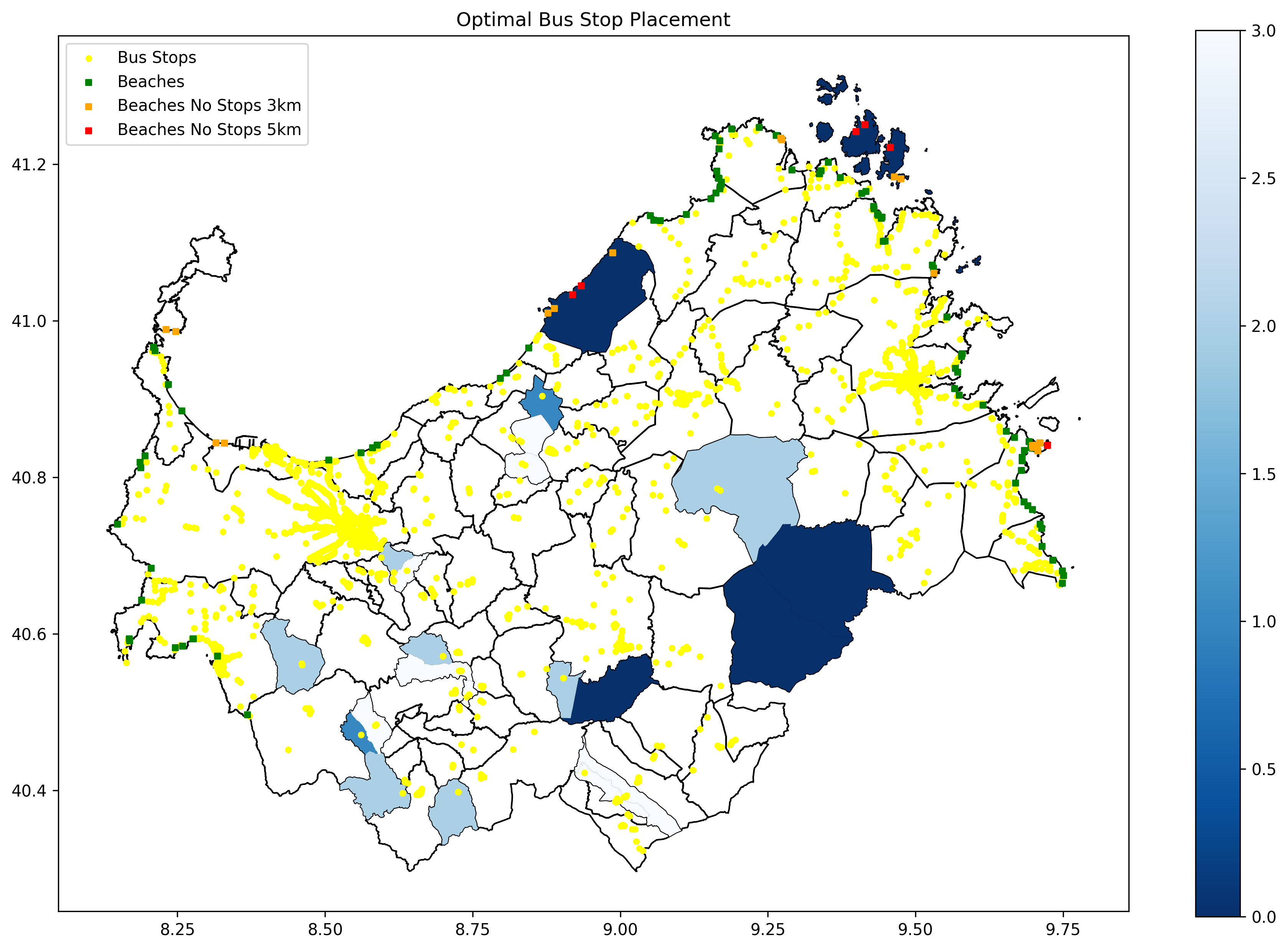
Mobility in Northern Sardinia | Data Science Lab on Smart Cities, UniMiB (2023).
In this project, we're diving into how people move around in the northern part of Sardinia, starting from the arrivals by airports and ports and focusing mainly on public transport stops to reach key facilities. Several indicators are calculated, accompanied by data visualizations. As for airports and ports, the project aims to examine the flows both on a seasonal basis, differentiating by the airport of arrival and departure, and by checking the number of domestic and foreign tourists. The analysis then focuses in particular on the situation of public transportation for tourists, analyzing their current conditions and the possibility of reaching popular destinations such as beaches, as well as for residents and connections to more populated areas.
Data World
Data Science | Data Analytics | GitHub
Collection of various data science projects (2021-now).
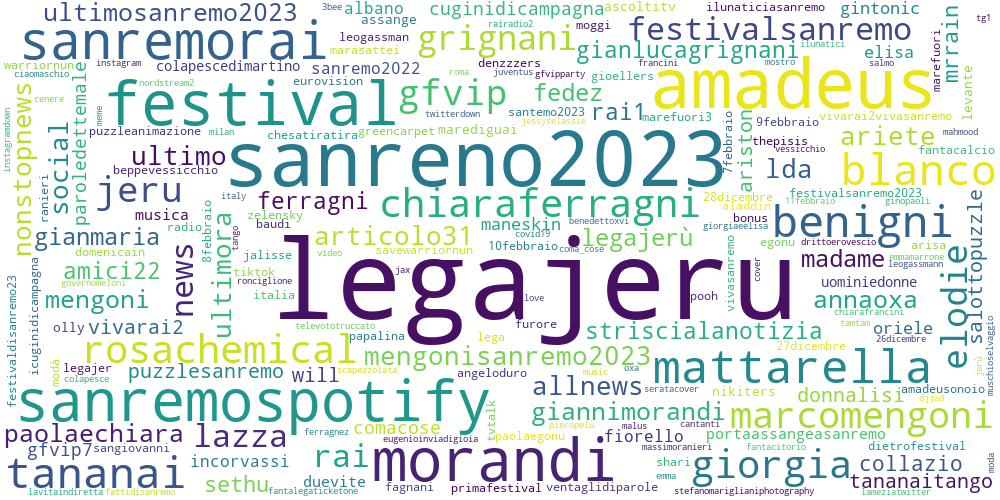
FantaSanremo
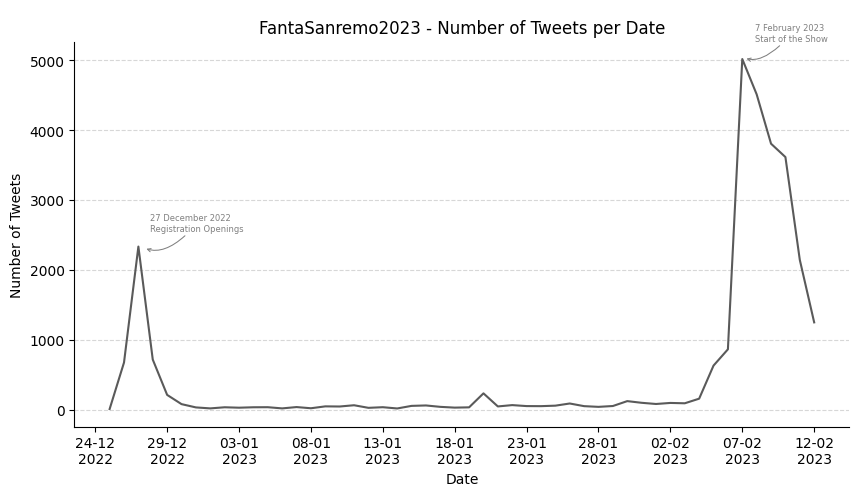
FantaSanremo 2023 - Trend and Sentiment Analysis
The 'Sanremo Festival' is becoming increasingly social. And so, companies and content creators also follow the events of the kermesse to stay up-to-date on any trends to be exploited and opportunities for growth. In recent years, 'FantaSanremo' - a game that involves viewers but also the singers in the competition - has become very popular among young and old enthusiasts. This project focuses on analyzing tweets related to the 2023 edition of #FantaSanremo, with the goal of analyzing content, the most relevant hashtags and sentiment related to the topic of interest.
The Office
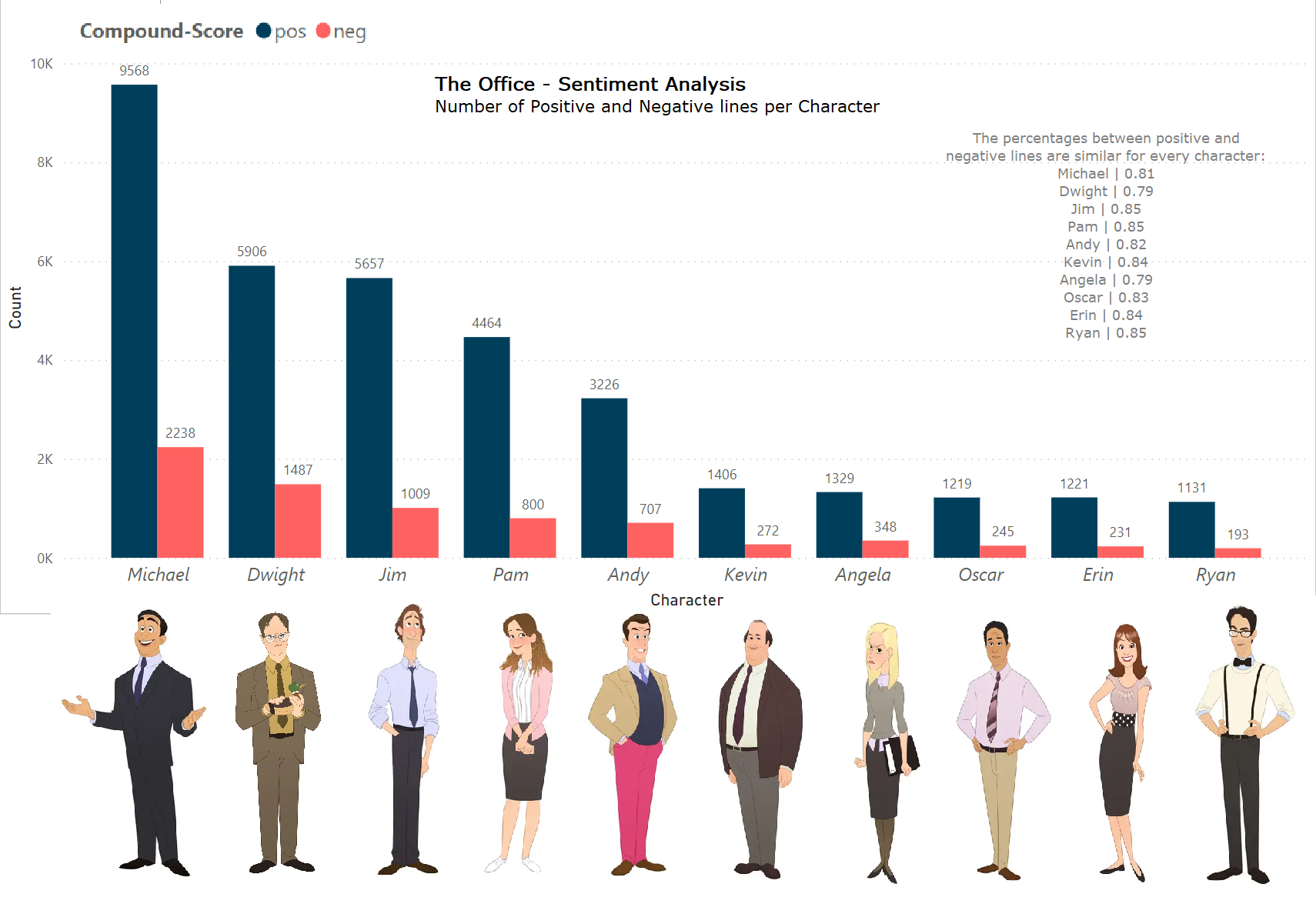
The Office GPT - Web Scraping, Sentiment Analysis and NanoGPT
"The Office" is an American mockumentary sitcom television series that depicts the everyday work lives of office employees in the Scranton, Pennsylvania branch of the fictional Dunder Mifflin Paper Company. In this project, all the lines from all the seasons of the TV show were scraped using BeautifulSoup. Subsequently, an exploratory data analysis and sentiment analysis of all the scraped lines were performed. The sentiment analysis utilized VADER to calculate sentiment scores. Finally, PowerBI was employed for the final visualization of the analyzed data.
Additionally, I leveraged the dataset I had created to experiment with the NanoGPT model, a small transformer-based language model introduced by Andrej Karpathy. In this scenario, I trained the model and experimented with it to generate various texts and ideas.
TV Ratings
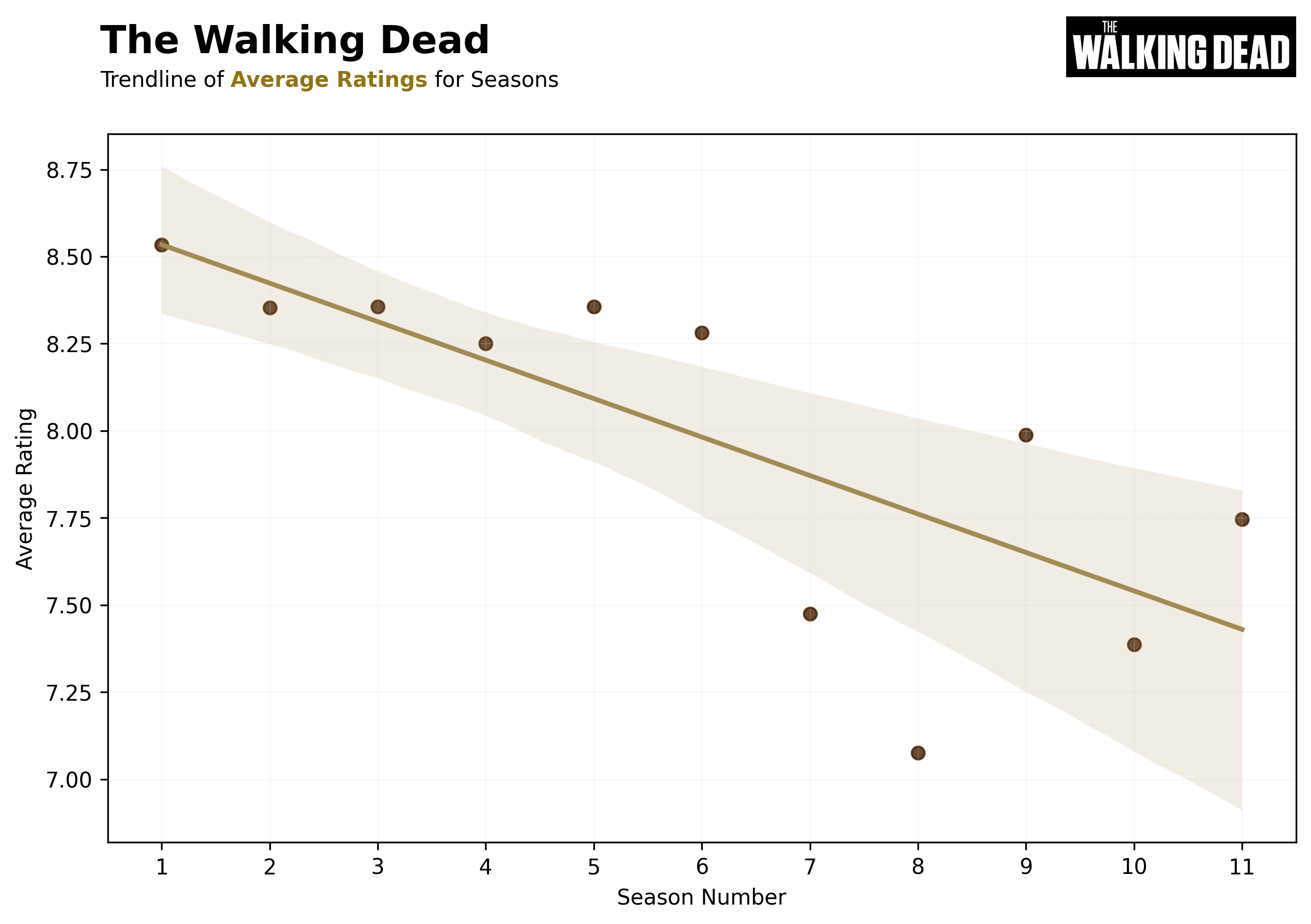
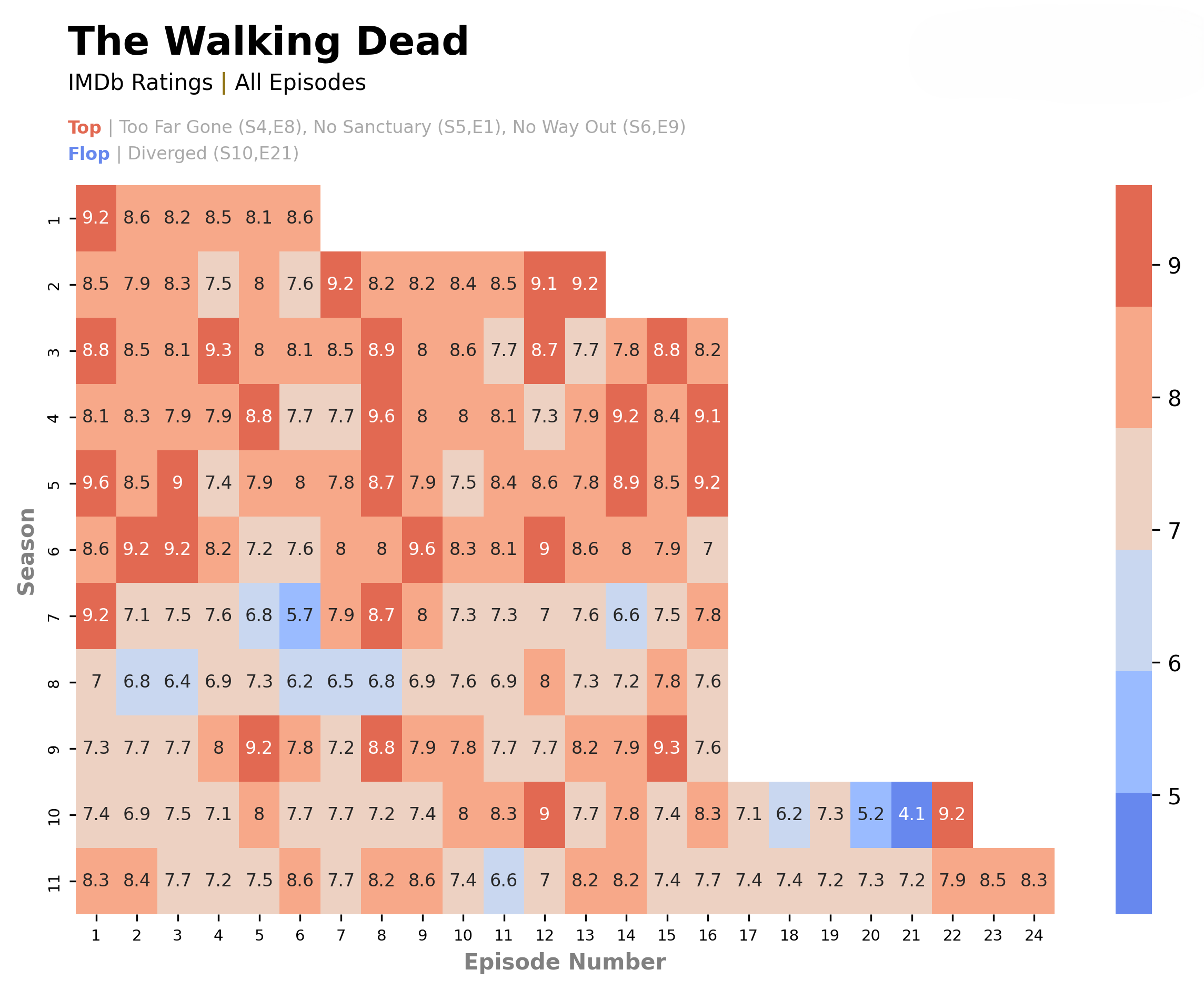
IMDb Ratings - Data Analysis
This project focuses on analyzing and visualizing IMDb ratings of popular TV series and films, aiming to uncover trends and patterns across seasons and episodes. The data visualization step employs two primary methods: trendline plotting, which provides insights on the show's performance over various seasons, and heatmap representations, providing a comprehensive overview of episode ratings across seasons.
Billboard Hot-100 EDA
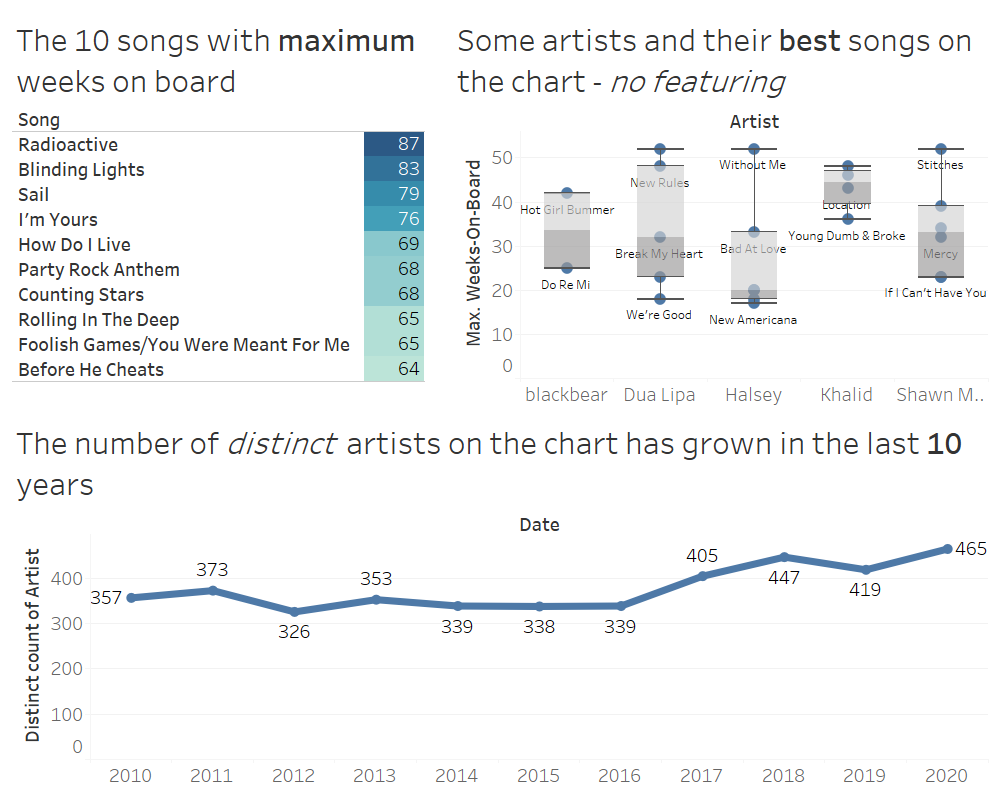
Billboard’s Hot-100 Weekly Charts - Exploratory Data Analysis
The Billboard Hot 100 is the music industry standard record chart in the United States for songs, published weekly by Billboard magazine. I've conducted an exploratory data analysis of the Billboard dataset containing all the charts from 1958 to today using SQLite. Finally, I've visualized some of the results in a dashboard created with Tableau.
Morbius
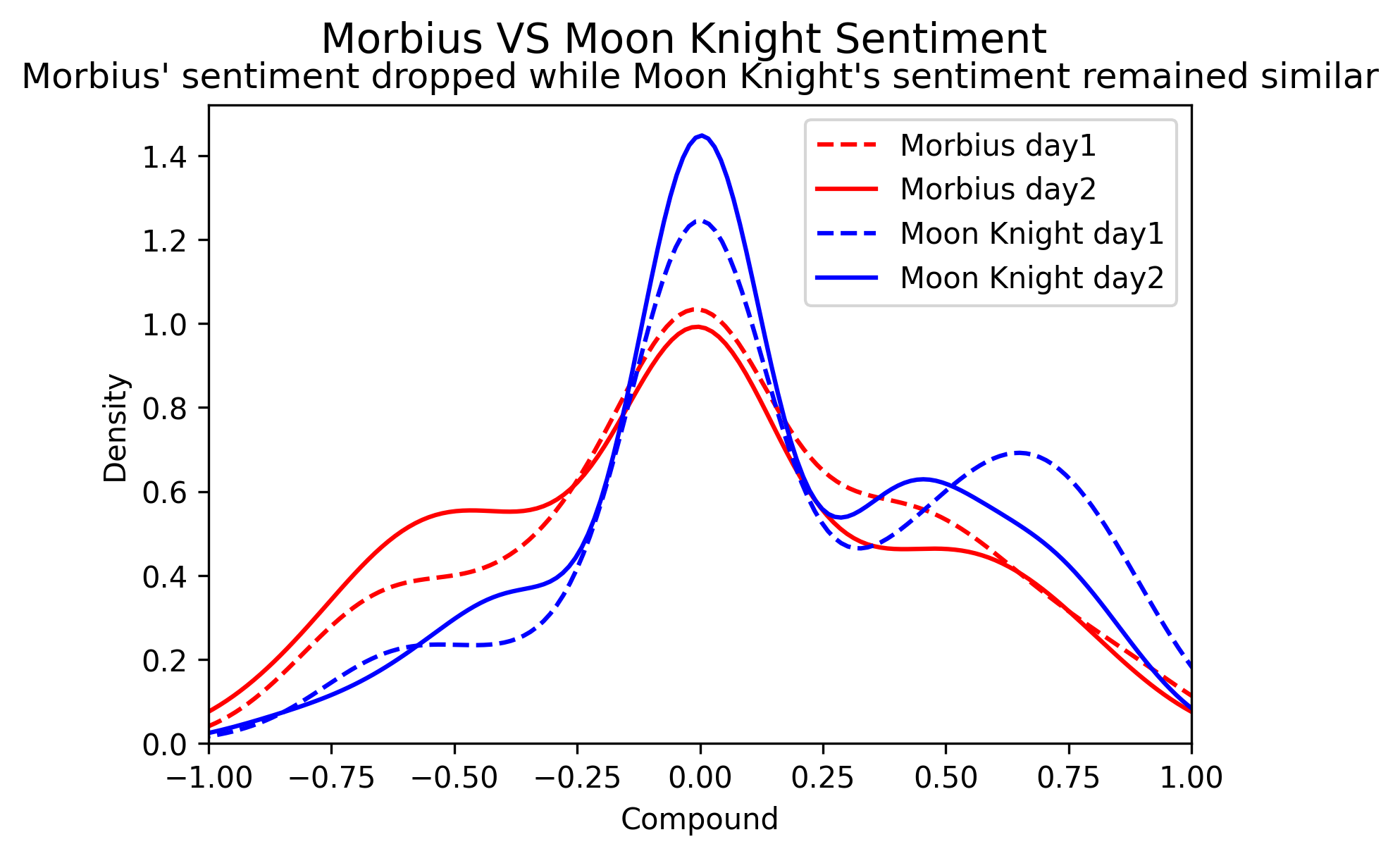
Morbius & Moon Knight - Sentiment Data Analysis
"Morbius" is a film from the Marvel catalogue. Tweets containing the keyword 'Morbius' were collected using the Twitter API and the Tweepy package to analyze the sentiment following the film's release. Sentiment analysis was conducted using VADER to calculate sentiment scores. The data was collected over the subsequent 4 days and then compared using a kdeplot. Additionally, data for the "Moon Knight" TV series, also from the Marvel Cinematic Universe, was collected for two days following the series' release. This data was then compared to the first two days after the release of "Morbius".
Serie A xG
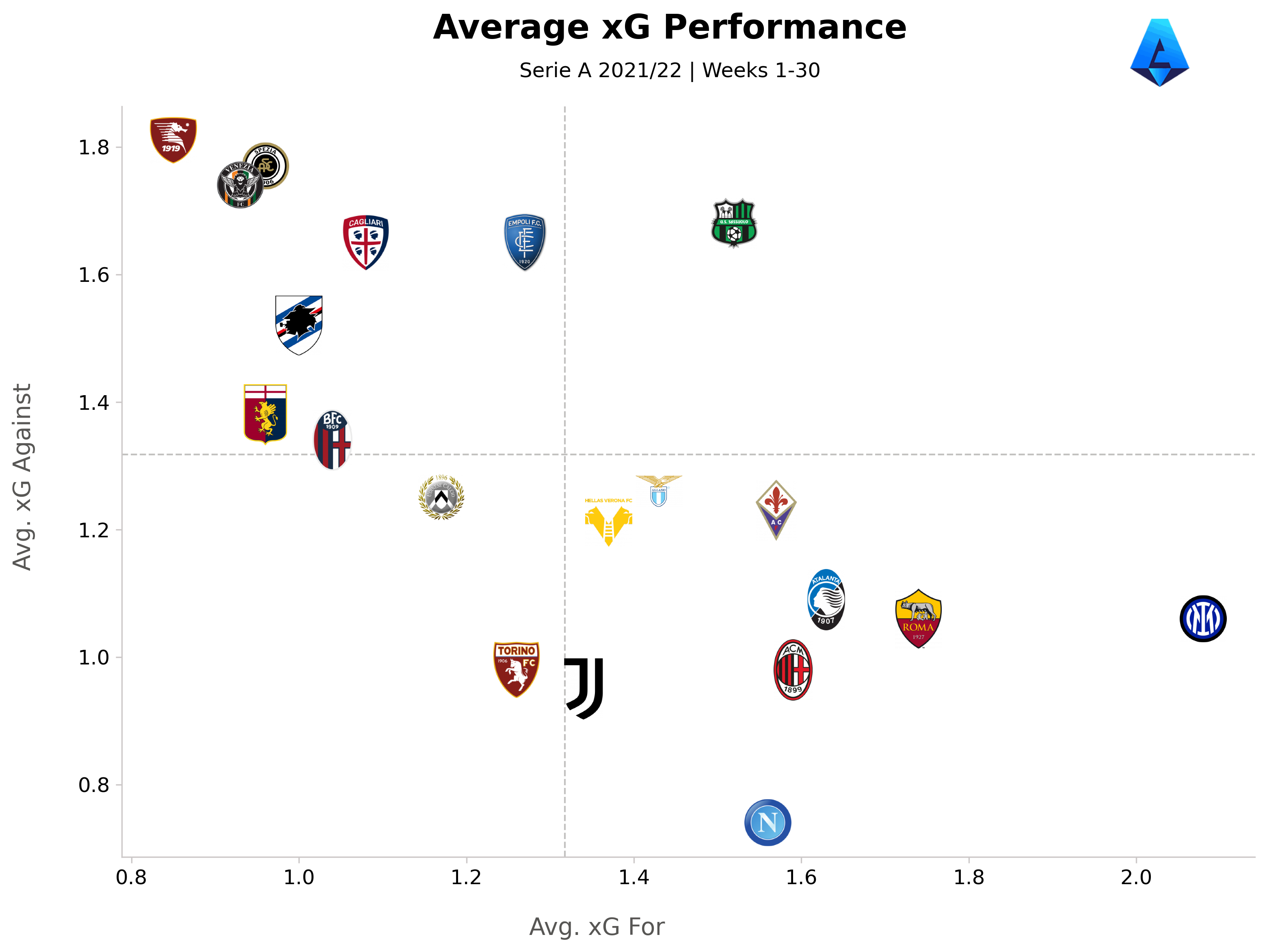
Serie A Expected Goals Performance - Web Scraping and Exploratory Data Analysis
Web scraping of data from the FBref website was conducted to analyze the current state of the Serie A Italian football championship using requests and BeautifulSoup. At the time of the project, the break for national teams had left the league with 8-9 games remaining, with many situations yet to be determined. These final matches could significantly impact the outcome of the season, potentially transforming it from an extraordinary one to a lackluster performance, or vice versa, depending on whether teams achieve their goals.
The dataset includes traditional football data along with xG, a metric used to assess expected goals for and against each team.
Football Analytics
Football Analytics | GitHub
Collection of various football analytics projects and visualizations (2021-now).
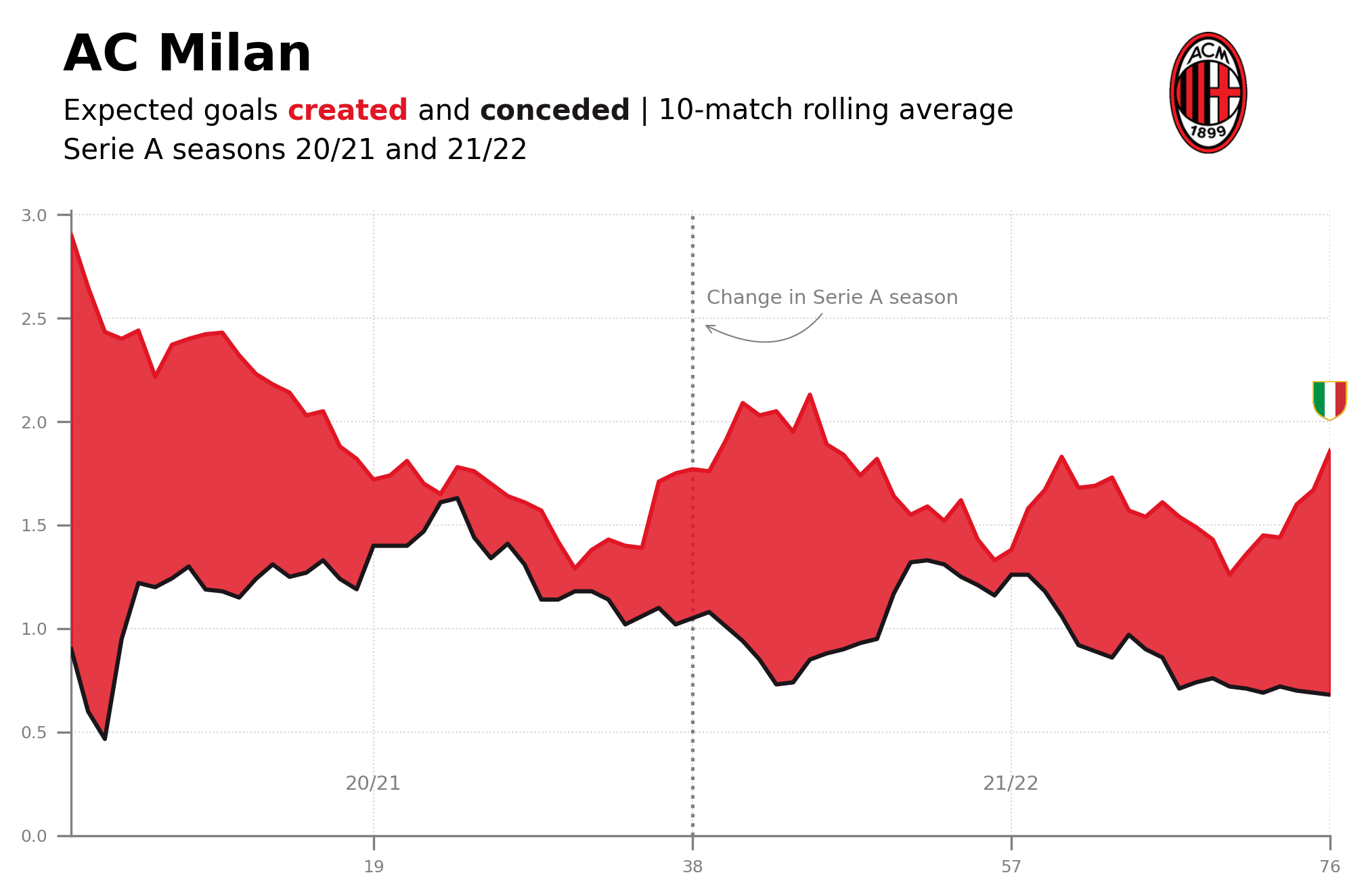
xG Rolling Plot | Code
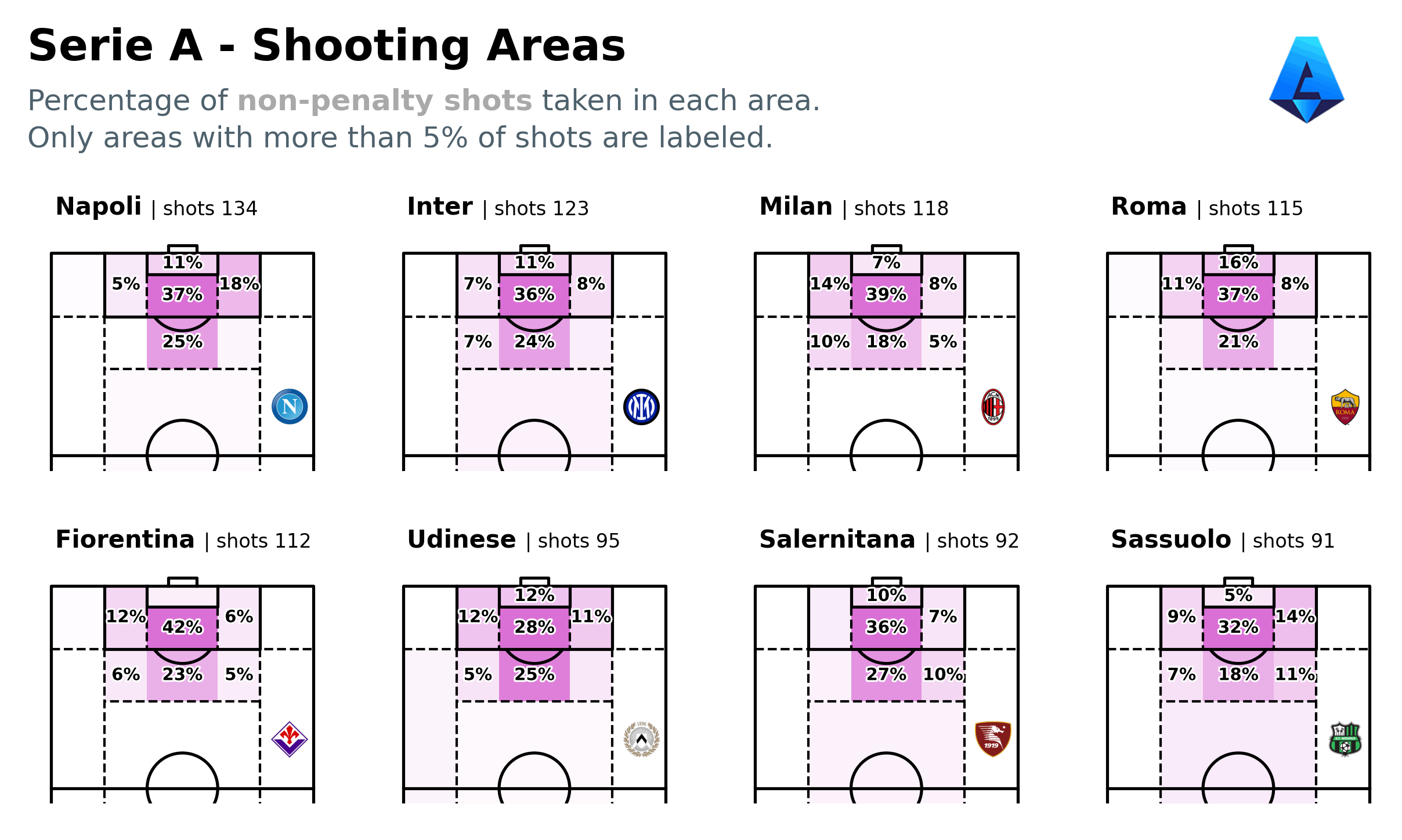
Tiled Shots Map | Code

xG Lollipop | Code
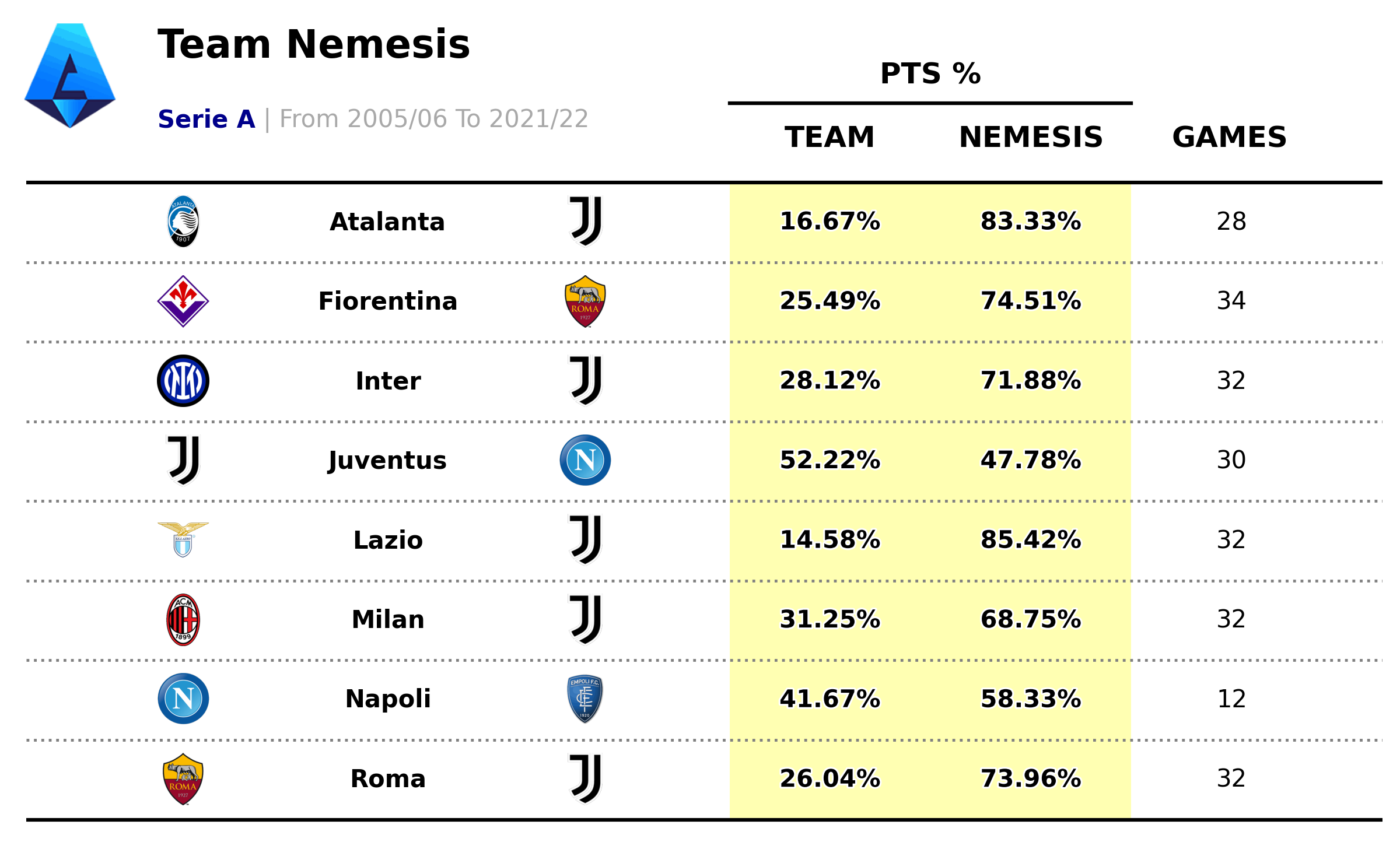
Team Nemesis | Code

Plottable | Code